Pinot in YouGov
As one of the server-side developers in a product called BrandIndex, one of our tasks is to keep analytics logs for the usage of the website, in a way that we can better understand the usage of it. The most important aspect of our website is running analyses on timeline data for our customers to get a better understanding of their brand positioning on their market, and these internal analytics gather information that help us to understand their interests so that we can keep improving the website itself by improving or adding more features that could be more valuable for them.
The problem
Up to a certain point the product used good old PostgreSQL for storing those logs. While this worked well enough for some time, we started having huge performance issues with it - not because of PG itself, which is amazingly fast, but because it's not the appropriate technology for doing OLAP stuff (it's more appropriate for OLTP instead), so no matter how much we tried to optimize our queries they were just not performing well enough. While there are PG extensions we could use to make it perform better in such cases, we wanted to explore a more appropriate technology for that end. At that time, PG was taking up to 10 minutes, or even more, to respond to our queries, which was leading to the load balancer cutting the requests by timing them out. To a point that YouGov staff started asking us to run PG queries directly on the database to gather analytics data for them - and we didn't want to spend any more time doing that instead of actual software development!
What to use?
The problem was clear, and the solution was superficially clear: we needed an OLAP-focused database. What to use, though, with the plethora of technologies available out there?
So we had to start by outlining our needs: we needed a database that would be optimized for reads, to run these queries as fast as possible, and to optimize the data storage in such a way to keep consistently good response times. So our idea was that a columnar database would probably be ideal, and that partitioning by date would also be helpful. And knowing that our logs contain data that is represented by multiple values, having a database that could handle collections of values would be a bonus, to avoid us having to repeat rows for having different values.
There were a number of contenders, then, that we could experiment with to then decide what to use for that purpose.
The reference: PostgreSQL
Since we already worked with PG, it was our reference for testing alternatives and see how they would perform.
We chose a sample of 100k analytics logs for our experiments - because 1M logs was too much and would make the experiments too slow for us. With this sample, we established a base database query, which for PG, using JSONB as the main log content field, took around 460ms to run.
Postgres + ARRAY
Our first experiment was actually by using PG itself, but storing data in arrays of values, instead of a big JSONB blob, expecting it to perform better because of the simpler data structure. And it actually did: our queries ran in ~75ms, meaning ~5x faster than using JSONB. This was already a considerable win, but it might not be enough for having a good user experience, so we wanted to push further by testing other technologies.
Apache Druid
Apache Druid was one of our first alternative picks for experimentation. It performed really well and gave us query times of ~120ms before results got cached, which was better than the baseline, but not as good as the PG + ARRAY approach. However, after the result was cached, it took ~40ms to run, therefore faster than PG + ARRAY. We were expecting a bit more, to be honest, but maybe we didn't optimize it as well as we should before judging its performance, but this was enough for us and it was a decent alternative.
In terms of setting it up, for development it was quite easy to put up and run it, but we haven't tried it in production.
Apache Pinot
At least at a first glance, Apache Pinot looked very similar to Druid for us. But then we started understanding its differences and how it employs a few different technical approaches that were very promising to us (like Apache Helix). For experimenting it, it was not a breeze as was Druid; It took us some time to figure out how we could put it up via docker-compose, and how to create our tables in it. But as soon as we figured it out, the process became straightforward.
In terms of performance: it took ~40ms on a first run, then ~9ms on the second run, probably because of optimizations taking place in Pinot components. Now we're talking! These were amazing results for us, and Pinot became our new "winner". But we still wanted to experiment other technologies and see what we could come up with.
ClickHouse
ClickHouse was the easiest alternative database that we setup in development. And it was quite easy to use too, publishing data to it was straightforward. Its performance, though, was not very promising: ~65ms for the baseline query. A bit faster than PG+ARRAY, but not as fast as we hoped.
ScyllaDB
ScyllaDB caught our attention by being the "faster cousin of Cassandra"; We really wanted to test it, and see how it could perform, but at the time we tested it, it didn't support indexing columns with Set types - which was a necessity for us, because Cassandra is not able to run decent filtering on columns that aren't indexed (it even requires a specific query statement modifier to force it to filter, to let the developer know that it's going to be slow). So we just scratched it. It was fairly easy to setup though, for development.
Apache Cassandra
Since Apache Cassandra was already at version 4, it did support indexing Set columns, which was a requirement for us. However, because filtering "rows" fast enough requires creating indexes in Cassandra, and we needed to basically filter on all columns, we had to index each of the columns; This was probably the reason why our performance with it was a bit dreadful: ~804ms, even slower than the baseline PG queries (almost twice as slow!). Which made us remember that Cassandra is very good for fast writes and for reading large chunks of data with very specific indexes, but not very appropriate for OLAP. Therefore, not the right tool for the job.
Results
The clear winner was, then, Apache Pinot. It worked well, and it performed amazingly, which was our main concern.
We needed some time, however, to put up a Pinot cluster up and running. After a while, we finally got the cluster up, and started publishing analytics logs to it. After this, we created an alternative admin page that the YouGov staff could use for running analytics over Pinot data instead of PostgreSQL. And it proved to be a success! Now we could finally have users having a UI that responded fast to gather knowledge about our customers, plotting the data into charts and ranking them!
Here's a chart comparing them (milliseconds, lower is better):
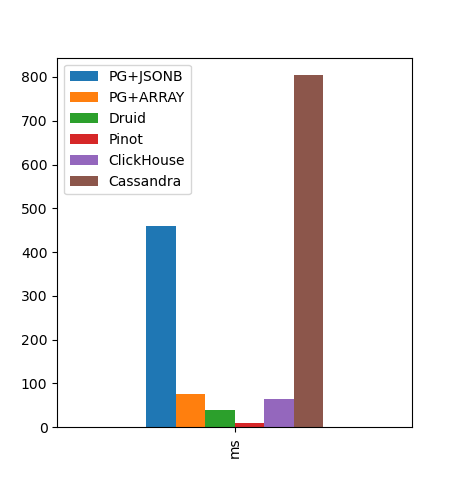
Above: Chart comparing the competing databases
Things we learned and pitfalls
In general, we learned a bit about each of the technologies we experimented with, but having started to use Pinot we also learned a bit more about it too. It has been serving us quite well, and we planned to use it even more in the future, for other purposes.
Deep Storage
Initially we thought that the concept of "Deep Storage" was something auxiliary to Pinot, and that it was totally optional. We thought it was just an extra layer of protection via backups, but it is actually fundamental for running Pinot in production environments. We learned this the hard way: one of our servers quickly reached the local disk storage limit, which was small.
As soon as we configured our cluster to use Amazon S3 as the deep store, we started having our Pinot segments committed and flushed to S3 instead of local disks, and everything was fine again.
Migration
We had to migrate our Pinot cluster to another node group, in AWS, and I made a big mistake: I didn't commit the currently consuming segments and flush them to the deep store, and after we migrated the cluster we lost a small portion of the data - representative of only a few hours of data, so it was not a huge deal, but certainly a problem we didn't want to have.
Next time we have to face something like this we will, instead, stop consuming new events from Kafka, flush the consuming segments to the deep store, and only then migrate the cluster.
Thanks
I'd like to thank the IT Ops and SRE folks in YouGov that worked hard with us to have the Pinot cluster running and migrated, but a very special thanks too to the Apache Pinot community for helping us so much in having things running as expected and reliably. Their support is something out of this world!